
前言:給我爬!
妳曾經有過賽博倉鼠症發作,控制不住瘋狂囤積資源的經歷嗎?
如果有,那我將會給妳頒發一個「人力爬蟲」的獎盃。
不幸的是,有一些已經病入膏肓的賽博倉鼠症患者,祂們已經不能忍受手動下載資源的重複操作,進而走上了自動化——開發爬蟲程序的道路。
我有一個朋友,祂就會使用程序定時更新自己的藏品……
然而,並不是所有人都像我這位朋友一樣淳樸。尤其是在「俺拾咧」撿便宜文化橫行的貴國,爬蟲更多地是一種被濫用的技術。羊毛黨用爬蟲來搜刮各個 App 上那一毛幾分的獎勵,內容農場用爬蟲來批量轉載文章到自己的網站,更不用提鋪天蓋地的腳本黃牛了。
有人的地方就有江湖,妖魔的橫行,給一項原本純粹的技術蒙上了嗨產的陰影,並直接促進了各種反爬蟲技術的發展。
我的朋友在被迫捲入這場軍備競賽之後,走了不少彎路,積累了一點微小的經驗。
本爬蟲系列主要介紹方法論和各種實用工具。限於篇幅,本系列將會分爲上下兩篇。
Contents
基礎爬蟲
相信有的群友看到這邊,已經開始躍躍欲試,要搭建自己的「Crawler as a Service」雲服務開始賺大錢了…… 請妳先出去。請妳發達了以後讓我過去上班,謝謝喵(
這裏我決定從頭講起,從一個理想的爬蟲世界開始,逐步前進到荊棘叢生的危險世界……
選擇工具
爬蟲的本質就是從網上下載一點甚麼東西而已,用到的工具可以簡單到一個瀏覽器,甚至是 curl。不過一旦考慮到未來可能要擴大規模,一個好用而且高性能的 HTTP 庫就必不可少了。這裏我選擇了 Python 的 aiohttp,支持異步多任務,簡單好用還功能強大。
當然妳也可以選擇 httpx 甚至隔壁的 Node.js 生態,方法論都是一樣的——從網上下載點東西。
爬 HTML
最簡單的爬蟲從下載 HTML 頁面開始。假如妳是一個勤奮的 E-Hentai 讀者,但是囊中羞澀,無法支付下載壓縮包的費用。於是妳決定做一點微小的工作,把畫廊裏面的每一個網頁都下載下來,直接從裏面提取圖片,最終合成一整本圖冊。
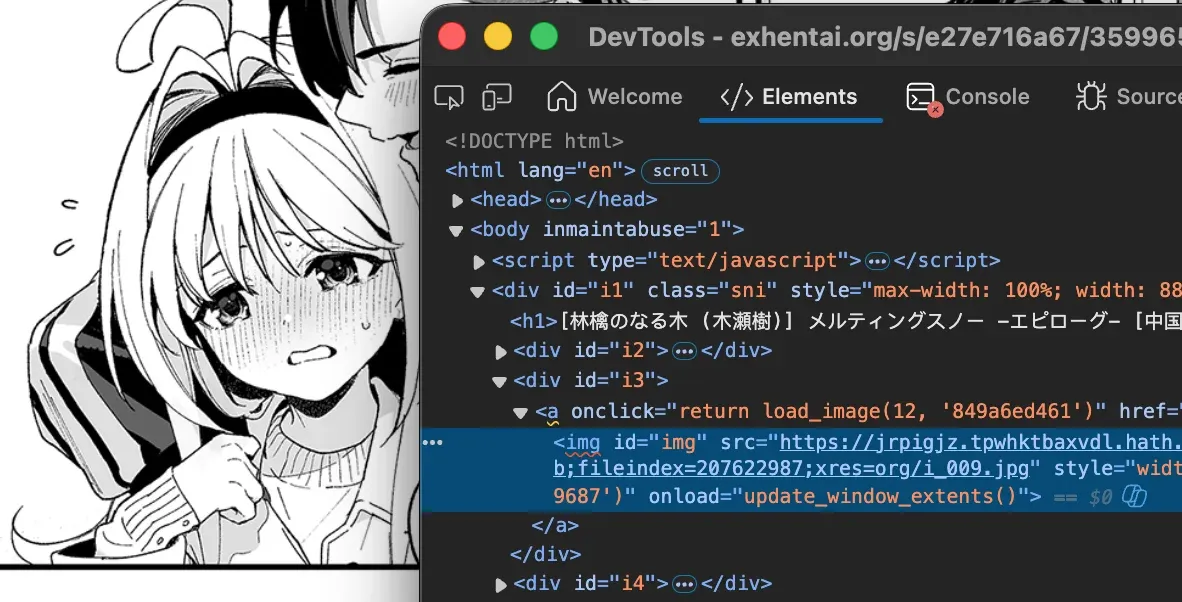
幸運的是,E 站並沒有阻止任何人爬上面的圖,HTML 代碼也萬年沒有變過了,屬實是輕而易舉。這不禁讓我覺得,許多人的爬蟲都是從 E 站入的門。
即使 HTML 爬蟲很基礎,它卻可以適用於相當一部分服務端渲染好 HTML 的網站,點擊就送,拿了就走。這種網站廣泛存在——各種博客、新聞網站、日本人寫的網站😁、論壇乃至許多色圖網站都屬於這一類。也許他們會在門上加鎖,但是無論他們在門上加了多少道鎖,只要能打開門,馬上就能拿到想要的東西。
開鎖的方法之後再說。我們用 aiohttp 下載完 HTML 之後,會使用 BeautifulSoup 4 (美麗湯 BS4) 庫將 HTML 字符串解析爲可以直接取值的 Python 對象。比如說上圖中,要提取該圖片的連結,我們可以先尋找一個 id 爲 “img” 的 <img> 標籤,再讀取該標籤的 src 屬性。簡單的代碼如下:
soup = BeautifulSoup(html_string, 'html.parser')
img_tag = soup.select_one('img#img')
img_url = img_tag.get('src')爬蟲的開發,來來去去,做到最後基本上都要從 HTML 中找到感興趣的 tag,再提取裏面的信息。好了妳已經畢業了。
第二行的 select_one 使用了 CSS 選擇器描述,如果妳用過瀏覽器裏面的 document.querySelector 函數,那一定對這種寫法不陌生。雖然說瀏覽器在處理 HTML 方面是絕對的專家,但是 BS4 快如閃電,故爬蟲的開發中能用 Python 完成的就不要麻煩瀏覽器。使用 Python 和 asyncio,能同時創建成千上萬個如同「下載👉🏻提取」之類的任務,這是瀏覽器做不到的。
BS4 教程 👉🏻 https://www.geeksforgeeks.org/python/implementing-web-scraping-python-beautiful-soup/
某群友用 Python 寫的高性能 E-Hentai 下載器 👉🏻 https://github.com/Galgamer-org/EH-PDF/
爬 API
爬蟲的另一個方向是提取 API 中的數據。許多 App 使用客戶端渲染模式,先加載一個空白 HTML 和 JS,再通過執行 JS 從 API 中拉數據,最後整理呈現到頁面上,更不用提有些軟件都不提供網頁版,只有手機 App 了。
此時如果直接去爬 HTML 將會一無所獲,再加上 Python 中也不能直接執行 JS,因此在 Python 中直接敲打 API 成爲唯一的選擇。
代表此類 App 的產品🈶️:
- 網易雲音樂
- X
- YouTube
API 輸出的都是純粹的數據,因此我們不再需要美麗湯,取而代之的是處理 JSON 或者其他數據格式的庫。不過大多數情況下,對於流行的產品,高雅人士已經爲我們把那些私家 API 都封裝好了,比如下面這些大名鼎鼎的——
萬一運氣太楣,想爬的 API 沒有高雅人士寫庫,那使用 aiohttp 來手撕 API 就不可避了。從分析 URL 開始,接着弄懂數據格式,再構造一個看上去合法的請求,一套流程下來,工作量不小,很可能還吃力不討好,還不趕快謝謝寫庫大佬,,,
爬 API 這種事情就非常的 Grey,這種遊走於灰色邊緣的快感有誰董……
當遇到要抓 API 數據的時候,瀏覽器的 F12 可以用來分析網頁版 APP 的網路請求和 JS 代碼。可是一旦分析陷入複雜,或者是面對手機版 APP,就需要更強力的工具出場了。
隆重介紹 Burp Suite!👉🏻官網

Burp Suite 是一個 HTTP 和 WebSocket 的分析、重放、篡改和測試工具,並且內置一個用於分析的瀏覽器,無需設置代理、證書……開箱即用,全部請求一目瞭然。
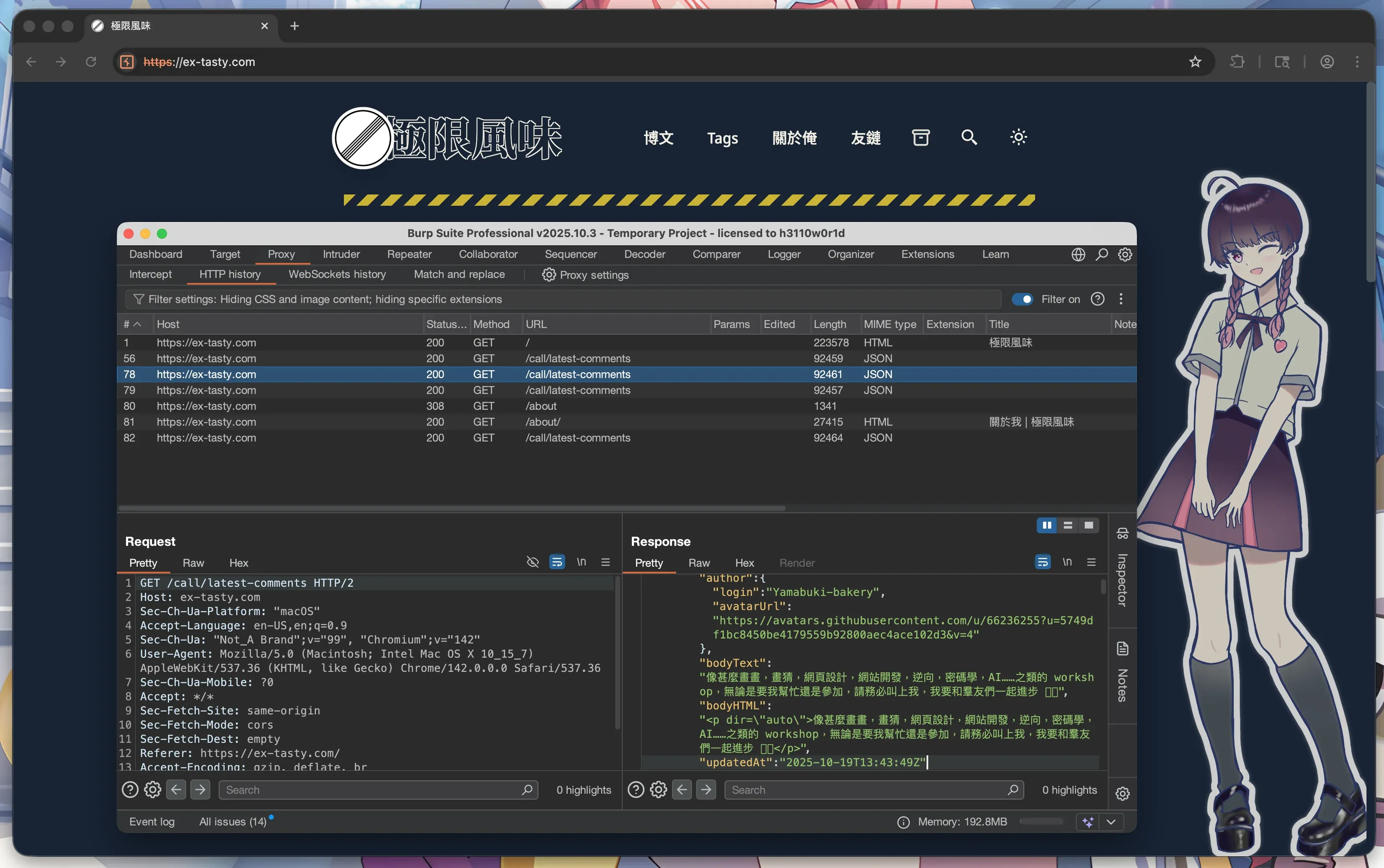
除了最最基本的 MITM 功能以外,Burp 還具有一個非常強力的,設卡攔截請求,並讓我來手動逐個確認放行的功能 (Intercept)。
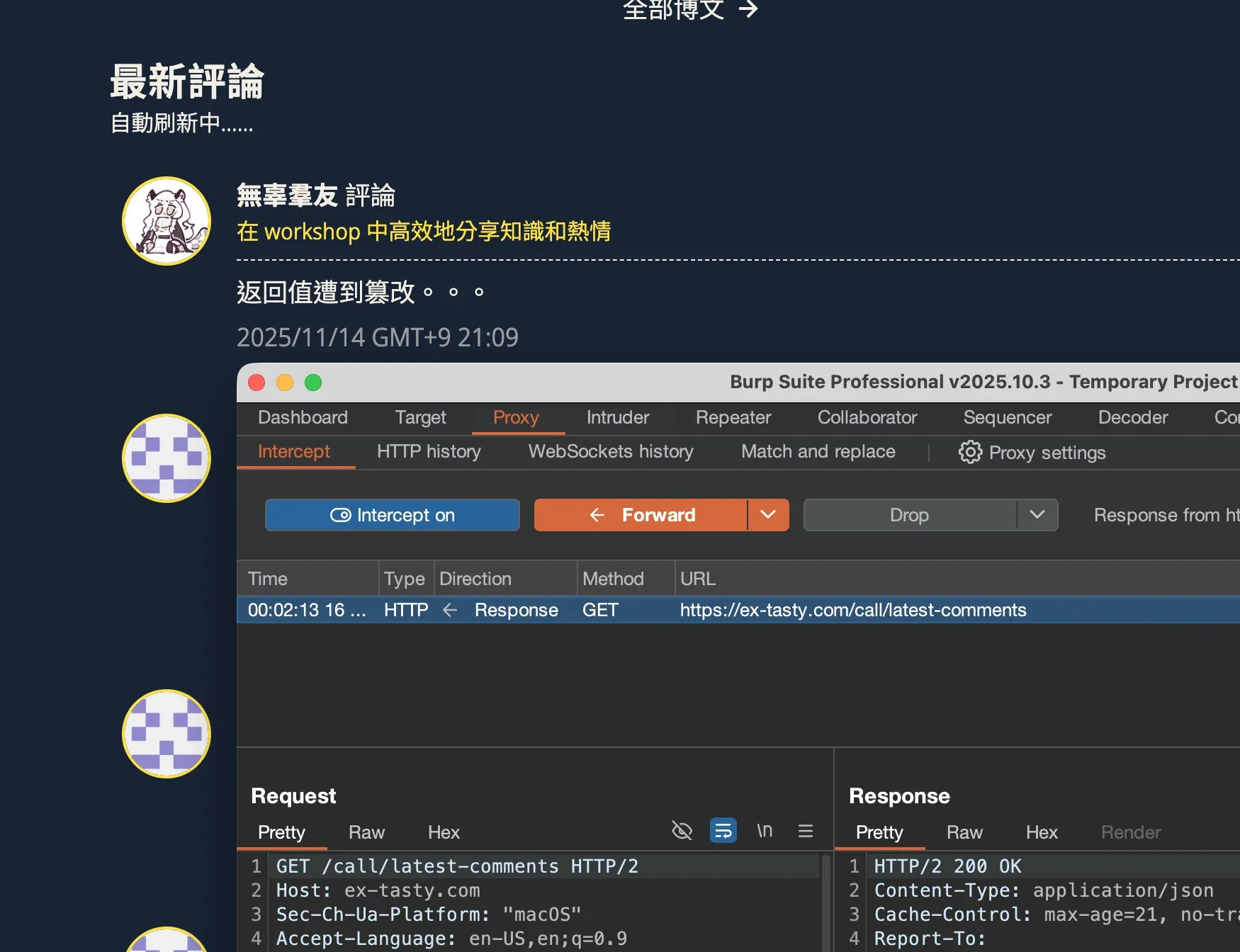
擁有了 Interceptor,分析過程中就可以隨時對請求體或者返回數據進行監視和修改,並觀察被分析目標的反應了。Burp 就是那麼強大,強大到它絕對不會誕生在中國和日本,因爲這兩國的法律會直接給開發者扣上幫信的帽子。
使用 Burp 分析手機 App 請求的方法,也遵循着「root 手機」-「安裝證書」-「破解 App」-「設置代理」的一般步驟,這裏就不再贅述了。
俺們在下文還會繼續用 Burp 來幹各種壞事 🥰
反爬繞過(上)
上面鋪墊了那麼久,那些衆所周知的廢話,我相信大家已經開始覺得無聊了。接下來我就要分享一些 😁 在實踐中得到的經驗,以及一批非常實用的工具。
本章的主題是「反爬繞過」。出於對自己保護網站利益,或者防止被刷請求等原因,現在的站長越來越喜歡引進各種反爬蟲技術。爬蟲開發者要想辦法繞過這些防護措施才能拿到有效的數據。這是一場無窮無盡的貓鼠遊戲,我也只是在歷史的長河裏面稍微游了游而已,如有補充,敬請在評論區發發表高見,非常感謝,,,
模擬登入狀態
先說一個歷史悠久,但是含金量經久不衰的攻防領域:模擬帳號的登入狀態。
想必妳早已在十幾年前就聽說過「QQ 防封要養號」「新號不能一次加太多好友」,也肯定有過「不登入就無法查看」的衝浪經歷。目前,各個網站平臺都喜歡通過驗證「登入與否」和「帳號誠信評分」來決定是否允許訪問內容,執行某些操作,甚至做出封號的決策。
目前,對於有用戶登入功能的網站,爬蟲必須具備模擬帳號的登入狀態的功能。大部分的網站和 app 會將登入 session 保存在 cookies 中,少部分會使用 Authorization header 來附帶 access token。
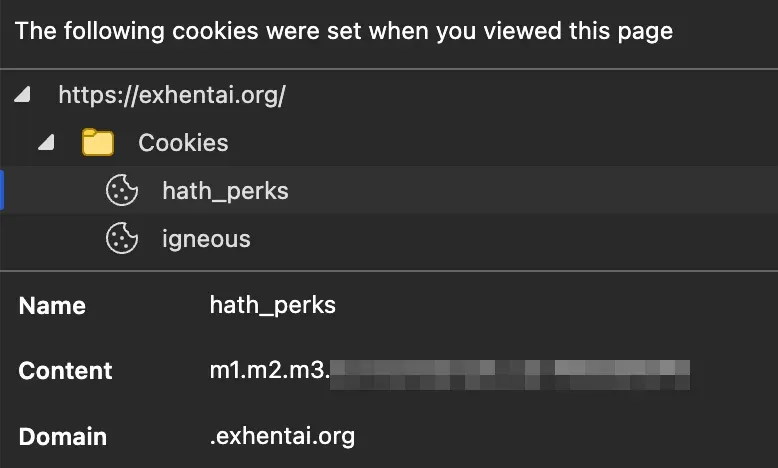
Aiohttp 可以很輕鬆地給請求添加 cookies 和各種 header,因此問題就來到了如何拿到這些 header。一種最簡單的方法就是使用人類在瀏覽器裏面完成登入,再把 header 們複製出來。該方法技術門檻極低,但是難以擴大規模。當需求擴大到需要大規模爬蟲農場,需要自動化取得 header 的時候,爬蟲內部就需要內置登入流程了。
幾乎可以肯定的是,目前絕大多數網站,都在註冊和登入的表單上添加了驗證碼保護。使用手機端 App 的登入 API 來登入確實是個繞過的好方法,可是對於純 web 版登入,「自動解決驗證碼」就是一個繞不開的話題了。
自動解決驗證碼
驗證碼這塊自古以來就是兵家必爭之地。自動程序會想盡一切辦法去自動消化驗證碼,而驗證碼也會想盡一切辦法來區分機器人和人類。這裏就是戰鬥最激烈的戰場。
傳統的變形文字驗證碼,已經在視覺 LLM 出現之後大規模潰敗,容我在這裏給他們上一炷香……
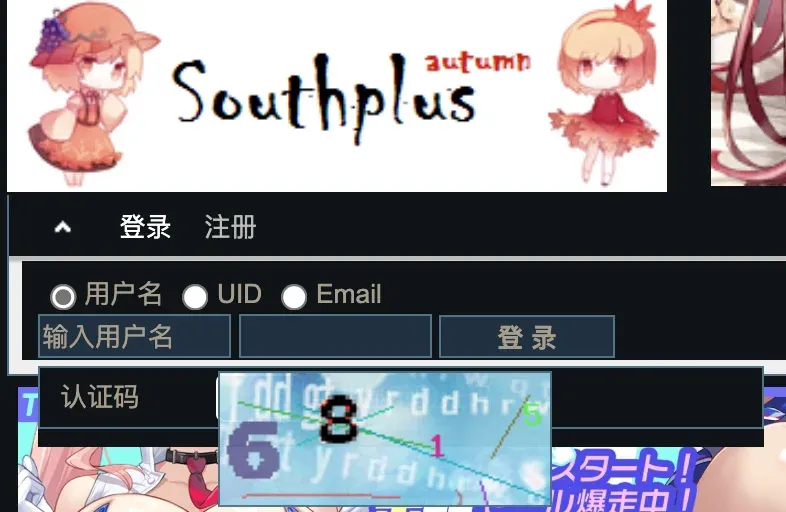

在識別準確性上,AI 無人能敵,就連我一開始也沒注意到圖中有一個淺綠色的「5」。
故現在的驗證碼廠商紛紛轉向了更高級的驗證碼,如「瀏覽器指紋」「遊玩小遊戲」「探測鍵鼠操作」和「深度學習詐術檢測」。其中,對付深度學習詐術檢測的方法本質上就是那一套風控和養號理論,包括不要操作新帳號,不要頻繁進行登入操作,要用乾淨的 IP 池等,這些屬於爬蟲的基本,不再贅述。
剩下的三種,其形式也五花八門,如:

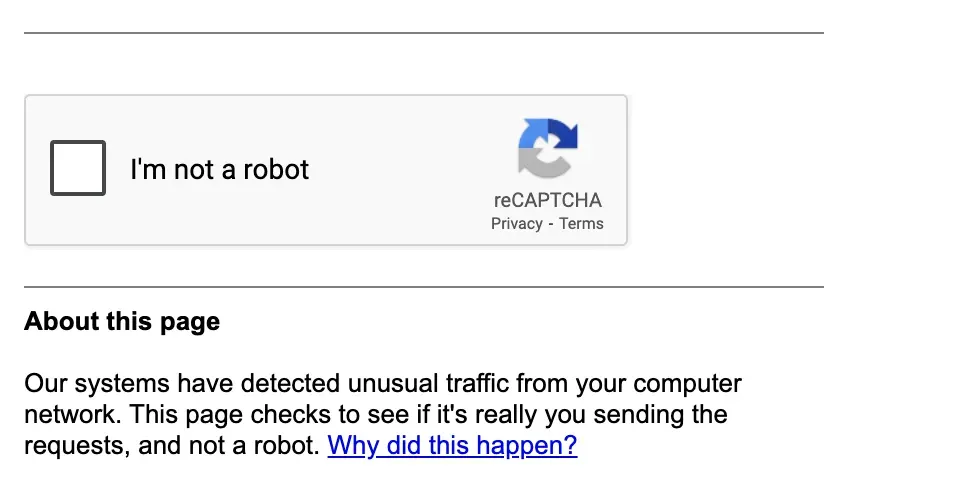

此外還有拼成語,旋轉 3D 物品,點擊文字,腦筋急轉彎等形式。如果要在這裏羅列所有驗證碼的解法,那將耗上三天三夜。並且,在谷歌上面搜索「常見 100 種驗證碼識別」很快就能找到能跑的代碼。實在輪不到我繼續造輪子。
上面所述的「20 種常見驗證碼」or「1000000 種常見驗證碼」,雖然外表上看上去五花八門,但是,他們的設計都基於同一個最基本的思路:
何意味?設想一下如果每個用戶都要先做題才能查看內容,用戶自然會放棄妳的網站。因此對全員投放驗證碼是一種傷敵一千自損八百的策略。網站必然有一套基準來判斷一個請求是否可疑,是否需要投放驗證碼,投放的驗證碼是何種難度,等等。
就像警察只會去盤查「形跡可疑」的人一樣,這給了我們可乘之機。
古話有雲:上醫治未病,中醫治欲病,下醫治已病。 當妳在與最複雜的驗證碼的戰爭中陷入僵局的時候,這是否說明,妳其實已經錯失了更好的機會了呢?還有一個衆所周知的淺顯道理——開車在路上,甩掉交警消星的最好方法,其實是一開始就不要驚動交警。
看大神轟轟烈烈地手撕最複雜的驗證碼固然震撼,但是在我們自己的小規模爬蟲項目中,做好良民的僞裝,配合上面所述的 cookies 注入,低空飛行繞過驗證碼,或者自動解決低難度的驗證碼,才是最簡便高效的做法。
幕間:Cloudflare Turnstile 的 Cookies
Cloudflare Turnstile 是一個被廣泛採用的網站反爬系統,其覆蓋面遠比谷歌的 reCAPTCHA 更大,也是許多爬蟲開發者遭遇的第一道門檻,這下不得不狠狠地手撕一下了。
Turnstile 看似威風,但是它在網路世界中的角色,其實就是一個門衛。如圖:
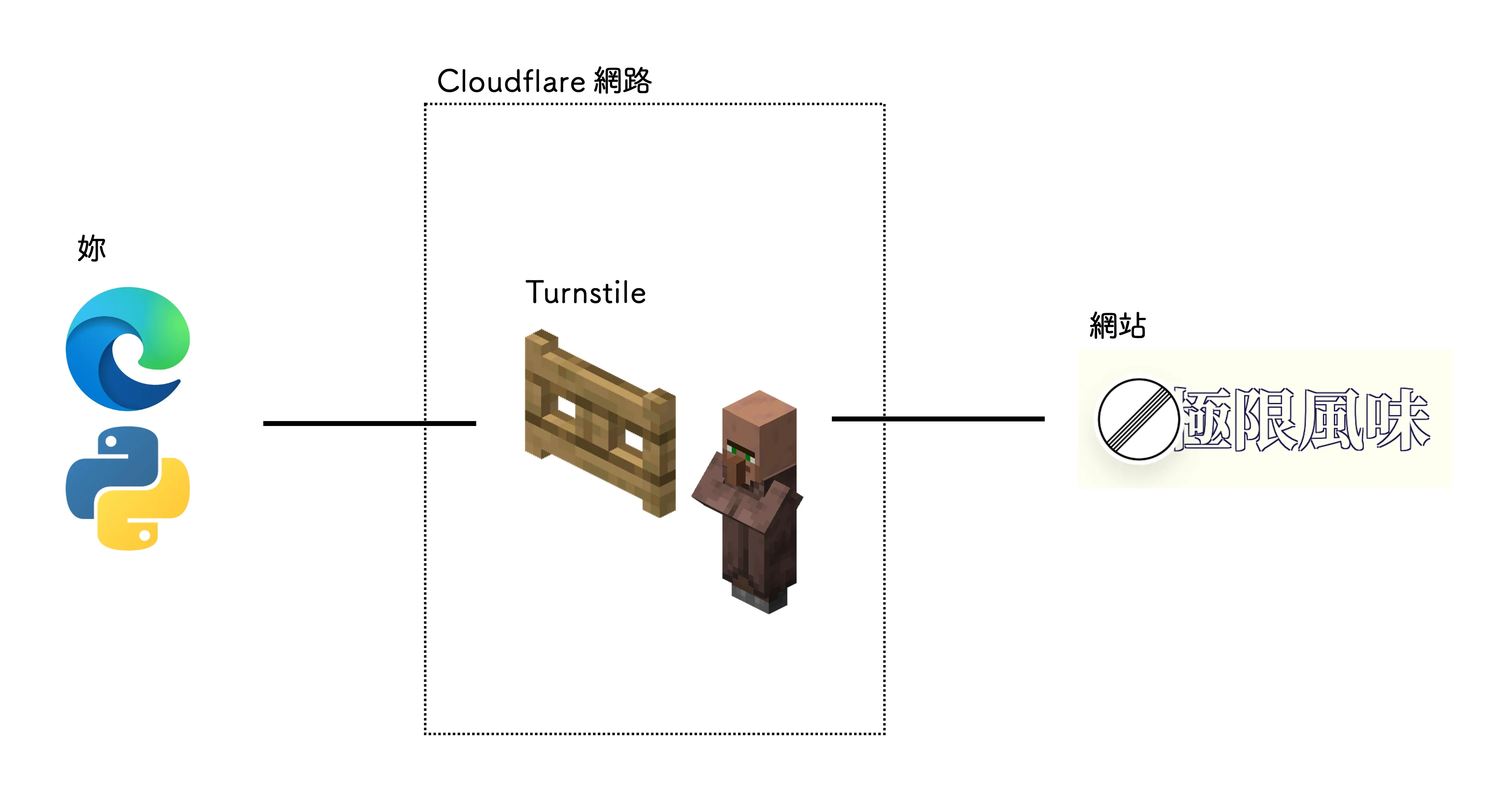
那門衛能做的事情,其實只有兩件:
- 放妳過去
- 攔妳下來查身分
Turnstile 會把第一次訪問的請求攔下來,並注入一個驗證碼頁面。該頁面會通過 JS 來檢測瀏覽器是否合法。如果合法,那麼 Turnstile 就會記錄該瀏覽器,並發放一個 cookies 字段 cf_clearance 作爲訪問許可證,然後放行。
並且,當請求被放行之後,它實際在網站上幹了甚麼,就已經完全不歸 Turnstile 管了。
於是聰明的群友肯定已經想到,只要把 cf_clearance 提取出來放到爬蟲裏面,就能順利通過門衛的檢查並爲所欲爲了。話是沒錯,當然妳的爬蟲也不能太囂張,該模仿的 header 還是要模仿,發請求也不能太頻繁,不然門衛還得再次把妳攔下來。我們在下一小節還會討論這個話題。
至此,Turnstile 就被一種樸素的方法輕鬆解決了……一半。
挑戰的另外一半,是要自動化地取得許可證 cookies。每次都手動複製粘貼 cookies 會影響爬蟲的效率。一般來說,解決此類 JS 驗證碼的最好方法就是使用自動化瀏覽器(Playwright 等)來通過驗證,並取得通行證 cookies。讓我們先來看一下整個流程是怎麼樣的:
只有認定的良民才可以全自動地通過 Turnstile,鼠標都不用點一下。但是可疑人員的待遇就完全不一樣了:
我只是換了一個地區和當前時區不一樣的 IP 地址,就死活過不去了。事實上,Turnstile 並不是除了放人就踹人的無腦二極管,而是一套會偷偷評估妳的「社會信用分」的系統,牠會通過分數來決定對妳進行何種處置。
社會信用分本質上就是風控系統,其算法大同小異。好奇的群友可以前往一 BrowserScan 來查看妳當前瀏覽器的信用分。
下圖是一個能自動通過 Turnstile 的高分瀏覽器:
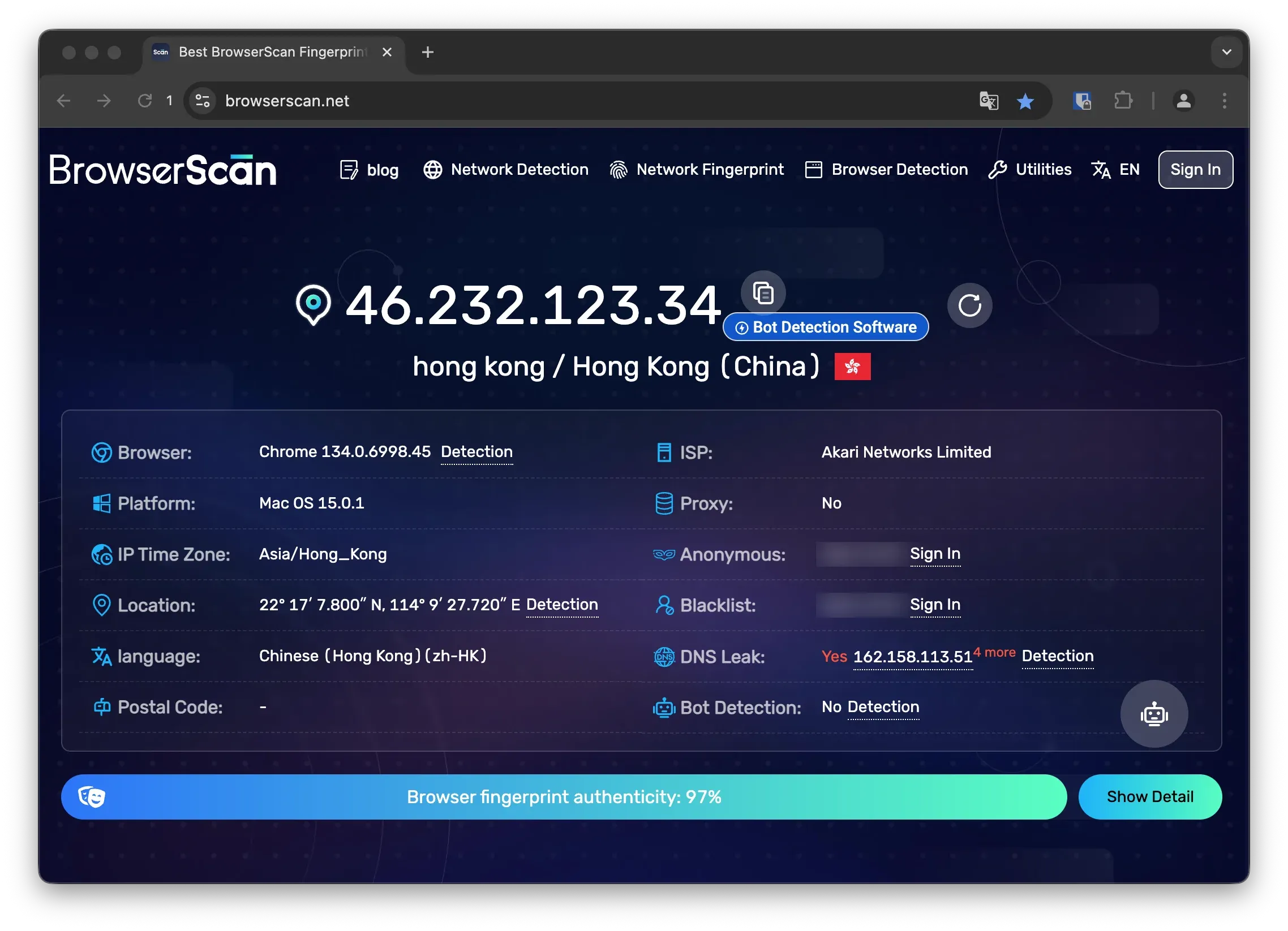
綜上所述,無論是爬蟲還是自動化瀏覽器,最重要的一點其實就是「低空飛行」,不要把時間浪費在那些纏鬥之上。即使妳沒法實現一個滿分的模範瀏覽器,但是看在妳良民面孔的份上,驗證碼也不會過度刁難人。而一些簡單難度的驗證碼是可以用插件和技巧繞過的:
小結
在上篇中,我先介紹了爬蟲開發的基本框架 aiohttp 和美麗湯,還有下載、解析 HTML 的方法,以及使用 Burp 調試 API 的基本要領。這些工具都很強大,用了一次肯定會愛上。
之後我介紹了反爬繞過措施中,模仿登入狀態的重要性,以及一些克服驗證碼的方法。當然,最有用的做法還是儘可能保持低空飛行,不要被雷達探測到,從而悄悄地繞開驗證碼。在下篇中我們還會繼續討論這個話題。
如果妳也是賽博倉鼠症,那我的朋友衷心希望本文能給妳帶來一點幫助和樂趣。
下篇預告
這篇文章比我想象中的內容要更多,請妳容忍我的分割商法,我將在下篇給妳們帶來一些好玩的東西 🥰
- 反爬繞過(下)
- 模擬真人快打瀏覽器 Header
- 設備信息模擬
- 幕間:爬爆大型平臺的正義性
- 模擬 TLS 指紋
- 壓 力 測 試
- 日式實踐笑話
- 結語
參考資料
Burp Suite
爬蟲小物
- 指紋瀏覽器 AdsPower https://www.adspower.net/
- 防檢測 Playwright 驅動 👉🏻GitHub
- 自動解驗證碼插件 Buster 👉🏻GitHub
- 免費代理 IP 池 👉🏻GitHub
- 人手鼠標指針軌跡算法 👉🏻GitHub
實用網站
- 驗證碼 Demo https://2captcha.com/demo
- 瀏覽器指紋檢測 https://www.browserscan.net/
自製爆改瀏覽器來逆向 JS 👉🏻博文
下次再見!👋🏻
 請停用 Dark Reader
請停用 Dark Reader
評論區
妳的評論和建議是我前進的動力!
我很需要妳的評論!無論長短還是水,我都會非常高興 😘